numen : the spirit of a place
via : the path to find it
Each numenvia tour is built around a single region and the creators who choose to make it their home — winemakers, bakers, farmers, artisans. You stay in one place, with plenty of time for conviviality, and leave restored and recharged.
Learn how we build a tour See our tours
A 7-day immersion in the Chianti hills — truffle hunting, cheese making, winemaking, Florentine artisan workshops, and farm-to-table meals in the countryside between Florence and Siena.
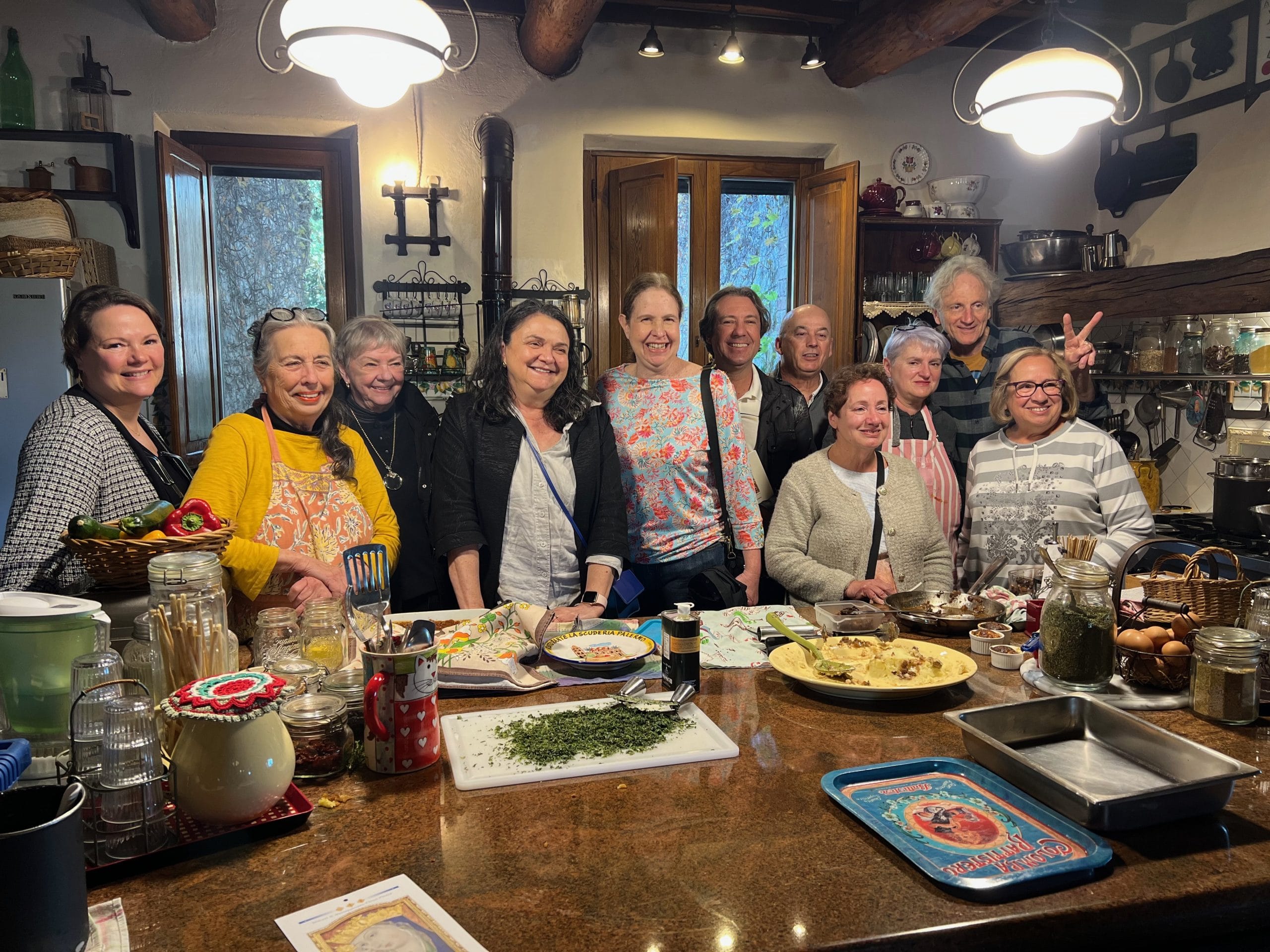
A 5-day journey through the UNESCO World Heritage landscape of Val d’Orcia — cooking classes, cheese making, flower farms, thermal baths, and Brunello wine tasting.

Reconnect with your roots in Basilicata, through the eyes of Adele Newton, whose family emigrated from Pisticci to Canada. Stay at a restored 16th-century farmhouse, walk the ghost town of Craco, make bread in Matera, and taste Aglianico del Vulture.

Join us in October for a special tour centered on Craco and the Festival of San Vincenzo, the patron saint of Craco. Walk the streets of the ghost town and celebrate with the Crachesi diaspora.
“The goats, the goat farm, the natural surroundings, all the ancient buildings and traditions that are still in use, all together really went right into my heart and made me feel connected, as if I had belonged to that land in some past life.”
Golijeh — Los Altos, California
“Giuditta was the perfect host for six magical days in Greve in Chianti. Time slowed down for me, my wife, and two kids, as we had beautiful, hands-on experiences with the makers of Greve. The truffle hunt/exuberant dog chase followed by shaving the truffles we found onto the pasta we made was a standout. A truly regenerative experience. Highly recommended!”
Anders G. — Los Altos, California
“Giuditta is a perfect guide, an organizer par excellence. Her local knowledge of the region, its hidden and other secrets as well as her connections with the community all served to make our trip to Greve unforgettable.”
Ratna O. — Toronto, Canada
We’d love to hear from you












































































